
TL;DR
- Client-Intelligenz: Kafka-Clients sind intelligent; sie müssen nicht den gesamten Cluster im Voraus kennen.
- Bootstrap-Server: Clients verwenden eine kleine Liste von
bootstrap.serversnur, um den ersten Kontakt mit dem Cluster herzustellen. - Metadaten-Erkennung: Nach der Verbindung mit einem Broker sendet der Client eine
MetadataRequest, um eine vollständige Karte aller Broker, Topics und Partitions-Leader zu erhalten. - Direktes Routing: Clients leiten Produce- und Fetch-Anfragen direkt an den Leader-Broker für eine bestimmte Partition, was das System hocheffizient macht.
- Automatische Updates: Clients halten ihre Metadaten automatisch auf dem neuesten Stand, indem sie auf Fehler (wie Leader-Wechsel) reagieren und sie proaktiv in regelmäßigen Abständen aktualisieren.
Wenn Sie zum ersten Mal mit Apache Kafka arbeiten, interagieren Sie mit Producern und Consumern. Sie geben ihnen eine Broker-Adresse, senden einige Nachrichten und lesen sie zurück. Es scheint einfach genug. Aber hinter dieser Einfachheit verbirgt sich ein eleganter und robuster Mechanismus, der es Ihren Client-Anwendungen ermöglicht, bemerkenswert intelligent und widerstandsfähig zu sein.
Aber warum ist es wichtig, diese Mechanismen zu verstehen? Für Entwickler und Betreiber ist ein tieferes Wissen über die inneren Abläufe des Clients entscheidend für die Leistungsoptimierung, die Fehlersuche bei kniffligen Problemen und den Aufbau wirklich widerstandsfähiger Anwendungen, die den unvermeidlichen Änderungen in einer verteilten Umgebung standhalten können.
Wie lernt ein brandneuer Client, der nur eine oder zwei Broker-Adressen kennt, die gesamte Cluster-Topologie kennen? Woher weiß er genau, wohin er eine Nachricht für Topic-A Partition 0 senden soll? Und was passiert, wenn ein Broker ausfällt und sich der Cluster ändert?
Dieser Beitrag wird diesen Prozess entmystifizieren und auf einfache Weise erklären, wie Kafka-Clients ihr Wissen bootstrappen, mit dem Cluster auf dem neuesten Stand bleiben und Fehler reibungslos behandeln.1
Der Bootstrap-Prozess: Der erste Handshake
Die Reise eines Kafka-Clients beginnt immer mit einem einzigen Konfigurationsparameter: bootstrap.servers. Dies ist eine Liste von einer oder mehreren Broker-Adressen (Host:Port), die Sie angeben.2
Hier ist ein minimales Beispiel in Rust mit der rdkafka-Bibliothek:
use rdkafka::config::ClientConfig;
use rdkafka::producer::FutureProducer;
let producer: FutureProducer = ClientConfig::new()
.set("bootstrap.servers", "kafka1:9092,kafka2:9092")
.set("client.id", "my-app")
.create()
.expect("Producer creation error");Diese Konfiguration teilt dem Client mit, wo er seinen Entdeckungsprozess beginnen soll. Der Client muss nicht die Adresse jedes Brokers im Cluster kennen; er benötigt nur einen Ausgangspunkt.
Folgendes passiert als Nächstes:
- Der Client wählt eine Adresse aus der
bootstrap.servers-Liste und versucht, eine TCP-Verbindung zu öffnen. Während dieses anfänglichen Handshakes werden auch Sicherheitsprotokolle wie SSL/TLS zur Verschlüsselung und SASL zur Authentifizierung behandelt, falls konfiguriert. - Wenn die Verbindung fehlschlägt (vielleicht ist dieser Broker ausgefallen), versucht er die nächste Adresse in der Liste, bis er sich erfolgreich verbindet.
- Sobald er mit einem einzelnen Broker verbunden ist, sendet er seine allererste Anfrage: eine Metadatenanfrage.
Das ist der Schlüssel. Der Client muss nur einen einzigen aktiven Broker finden, der als sein Einstiegspunkt in den gesamten Cluster fungiert.3
Interactive Kafka Client Simulation
See how Kafka clients discover brokers, resolve partitions, and handle data.
1. Client Configuration
The client only needs one or two initial contact points.
2. Produce a Message
Kafka Cluster State
3. Consumer Groups
Client-Side Log
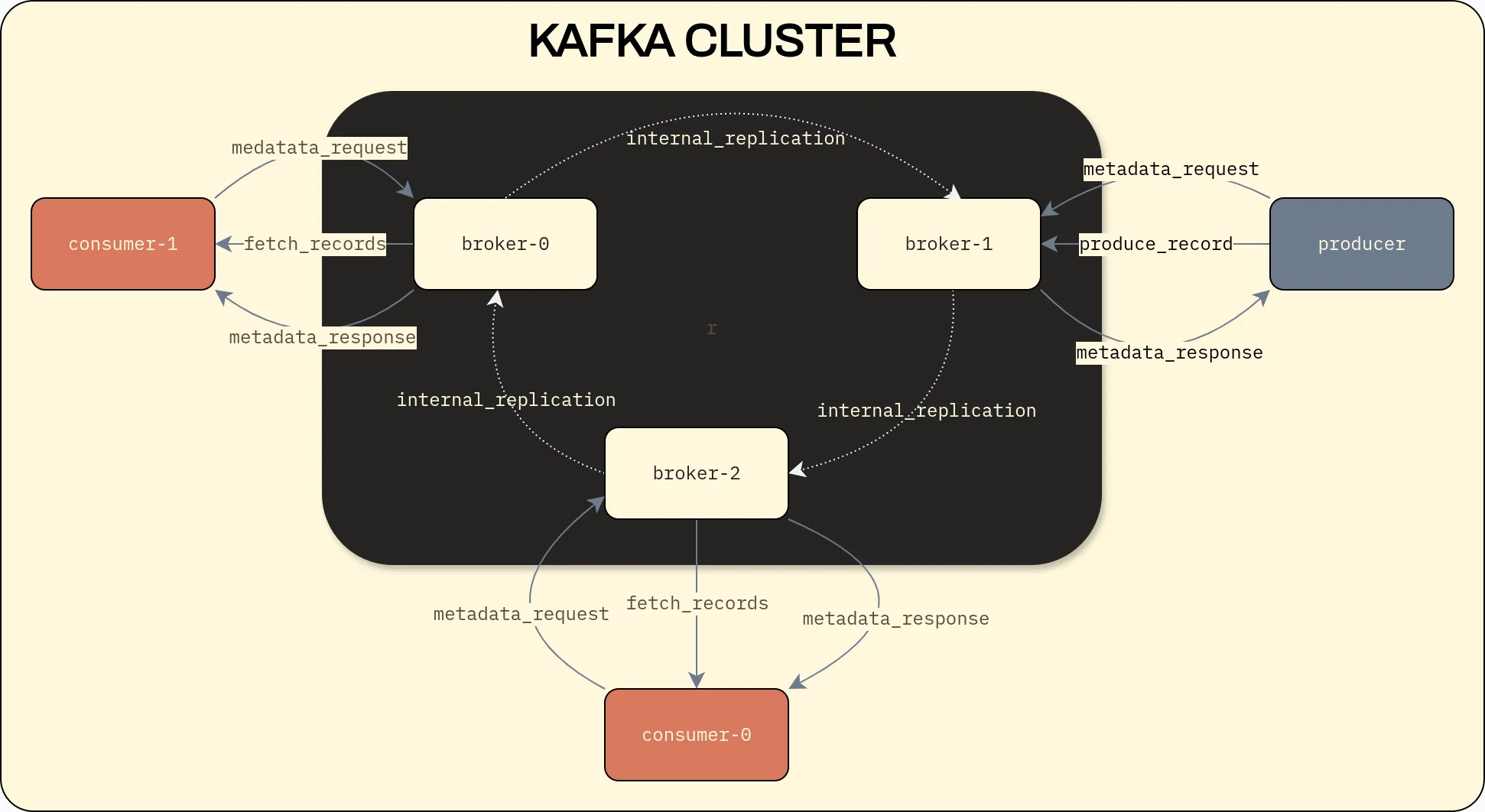
Entschlüsselung der Metadatenantwort: Aufbau der Cluster-Karte

Jeder Broker in einem Kafka-Cluster kann auf eine MetadataRequest antworten. Die Antwort des Brokers ist eine umfassende Karte des aktuellen Zustands des gesamten Clusters. Sie enthält wichtige Informationen, darunter:4
- Eine vollständige Liste aller Broker im Cluster, einschließlich ihrer Hostnamen und Ports. Der Client verwirft sofort die ursprüngliche
bootstrap.servers-Liste und ersetzt sie durch diese maßgebliche. - Eine Liste aller Topics im Cluster.
- Für jedes Topic eine Liste seiner Partitionen.
- Für jede Partition der Leader-Broker und der Satz von Replika-Brokern.
Die wichtigste Information hier ist der Leader für jede Partition. In Kafka müssen alle Lese- und Schreibvorgänge für eine bestimmte Partition an den Leader dieser Partition gehen. Broker lehnen Anfragen ab, die an einen Nicht-Leader gesendet werden.
Dieses Design ist ein zentraler Bestandteil von Kafkas “intelligenter Client, einfacher Broker”-Philosophie. Der Client ist nun dafür verantwortlich, diese Metadaten zu verwenden, um nachfolgende Anfragen korrekt weiterzuleiten. Der Broker fungiert nicht als Proxy; er stellt lediglich die Informationen zur Verfügung und erwartet, dass der Client sie verwendet. Der Client erstellt aus dieser Metadatenantwort einen In-Memory-Cache – seine Weltanschauung des Clusters.56
Die Datenebene in Aktion: Produce- und Fetch-Anfragen
Mit seinem gefüllten Metadaten-Cache ist der Client bereit, Daten zu senden und zu empfangen.
- Wenn Sie eine Nachricht produzieren: Der Producer-Client betrachtet das Topic und die Partition der Nachricht (oder bestimmt die Partition anhand des Nachrichtenschlüssels). Anschließend konsultiert er seinen Metadaten-Cache, um den Leader-Broker für genau dieses Topic-Partition zu finden, und sendet die
ProduceRequestdirekt an diesen Broker. Die Wahl eines Nachrichtenschlüssels ist entscheidend, um sicherzustellen, dass zusammengehörige Ereignisse in der richtigen Reihenfolge verarbeitet werden; eine detaillierte Anleitung dazu finden Sie in unserem Beitrag Warum Kafka-Ereignisse in der falschen Reihenfolge ankommen können.* Wenn Sie Nachrichten konsumieren: Der Consumer-Client weiß, welchen Partitionen er zugewiesen ist. Für jede Partition sucht er den Leader-Broker in seinem Cache und sendet eineFetchRequestdirekt an diesen Leader, um die Daten zu erhalten.
Diese direkte Kommunikation mit dem Leader ist ein Hauptgrund für die hohe Leistung von Kafka. Es gibt keine zentrale Routing-Schicht, die einen Engpass verursachen könnte.78
Umgang mit Metadaten-Updates und -Ausfällen
Kafka-Cluster sind dynamisch. Broker können ausfallen und Leader-Wahlen können stattfinden, wodurch die zwischengespeicherten Metadaten des Clients veraltet sind. Ein Client, der weiterhin Anfragen an einen Broker sendet, der nicht mehr der Leader ist, verschwendet Ressourcen. Wie halten Clients also ihren Cache aktuell? Sie verwenden eine Kombination aus reaktiven und proaktiven Aktualisierungen.
Reaktive Aktualisierung: Aus Fehlern lernen
Die primäre Strategie lautet “Cache bis zum Fehler”. Ein Client geht davon aus, dass seine Metadaten korrekt sind, bis ein Broker ihm etwas anderes mitteilt.
Mehrere Fehler können eine Aktualisierung auslösen, die häufigsten sind:
NotLeaderForPartitionException: Dies ist ein entscheidendes Signal vom Broker. Es bedeutet: “Ihre Informationen sind veraltet. Der Broker, an den Sie diese Anfrage gesendet haben, ist nicht mehr der Leader für diese Partition. Sie müssen den neuen finden.”9UnknownTopicOrPartitionException: Dieser Fehler tritt auf, wenn der Client versucht, in ein Topic oder eine Partition zu produzieren oder daraus zu konsumieren, die dem Broker nicht bekannt sind, was passieren könnte, wenn das Topic gerade erst erstellt wurde.
Wenn ein Client einen dieser Fehler erhält:
- Er markiert seinen aktuellen Metadaten-Cache als veraltet.
- Er sendet sofort eine neue
MetadataRequestan einen Broker aus seiner bekannten Liste. - Er empfängt die aktualisierte Cluster-Karte, findet den neuen Leader und aktualisiert seinen Cache.
- Er wiederholt die ursprünglich fehlgeschlagene Anfrage und sendet sie diesmal an den korrekten, neu entdeckten Leader.
Diese fehlergesteuerte Rückkopplungsschleife macht das System selbstheilend. Clients passen sich automatisch an normale Cluster-Ereignisse wie Leader-Wechsel an, ohne dass eine Fehlerbehandlung auf Anwendungsebene erforderlich ist.
Proaktive Aktualisierung: Warten Sie nicht auf einen Fehler
Sich nur auf Fehler zu verlassen, ist nicht genug. Was ist, wenn ein neues Topic erstellt wird? Oder neue Partitionen zu einem bestehenden Topic hinzugefügt werden? Der Client würde nie davon erfahren, bis er zufällig versuchte, auf eines zuzugreifen und scheiterte.
Um dies zu lösen, führen Clients auch eine proaktive, periodische Metadatenaktualisierung durch. Dies wird durch die Konfiguration metadata.max.age.ms gesteuert (standardmäßig 5 Minuten). Selbst wenn keine Fehler auftreten, sendet der Client in diesem Intervall automatisch eine MetadataRequest, um Änderungen wie neue Topics oder Partitionen zu entdecken.2
Fazit
Das Zusammenspiel von Bootstrapping, Metadatenanfragen und fehlergesteuerten Aktualisierungen bildet den intelligenten Kern des Kafka-Clients. Es ermöglicht einer einfachen Anwendung, sich mit einem komplexen, dynamischen und verteilten System zu verbinden und effizient und widerstandsfähig darauf zu arbeiten.
Indem die Routing-Logik auf den Client verlagert wird, vermeidet Kafka zentralisierte Engpässe und erreicht seine bekannte Skalierbarkeit. Wenn Sie das nächste Mal bootstrap.servers konfigurieren, wissen Sie, dass es nicht nur eine Serveradresse ist – es ist der Schlüssel, der die dynamische Karte des gesamten Kafka-Universums des Clients freischaltet.
Für einen übergeordneten Überblick über die Architektur von Kafka und ihre strategische Bedeutung lesen Sie unseren Leitfaden Apache Kafka für technische Führungskräfte.
Footnotes
-
confluent_kafka API — confluent-kafka 2.11.0 documentation ↩ ↩2
-
APACHE KAFKA: Common Request and Response Structure - Orchestra ↩
-
Does kafka metadata response alreays contains all brokers in cluster? - Stack Overflow ↩
-
Apache Kafka Broker Performance: A Brief Introduction and Guide - Confluent Developer ↩